Best viewed on a large screen with fast internet • Scroll/Pinch to zoom • Drag to pan • Image might take a few seconds to load after zooming






























* White: upscaled region (valid zoom area)
We present UltraZoom, a system for generating gigapixel-resolution images of objects from casually captured inputs, such as handheld phone photos. Given a full-shot image (global, low-detail) and one or more close-ups (local, high-detail), UltraZoom upscales the full image to match the fine detail and scale of the close-up examples. To achieve this, we construct a per-instance paired dataset from the close-ups and adapt a pretrained generative model to learn object-specific low-to-high resolution mappings. At inference, we apply the model in a sliding window fashion over the full image. Constructing these pairs is non-trivial: it requires registering the close-ups within the full image for scale estimation and degradation alignment. We introduce a simple, robust method for getting registration on arbitrary materials in casual, in-the-wild captures. Together, these components form a system that enables seamless pan and zoom across the entire object, producing consistent, photorealistic gigapixel imagery from minimal input.
Our system consists of three stages: Dataset Construction, Per-Instance Fine-Tuning, and Gigapixel Inference.
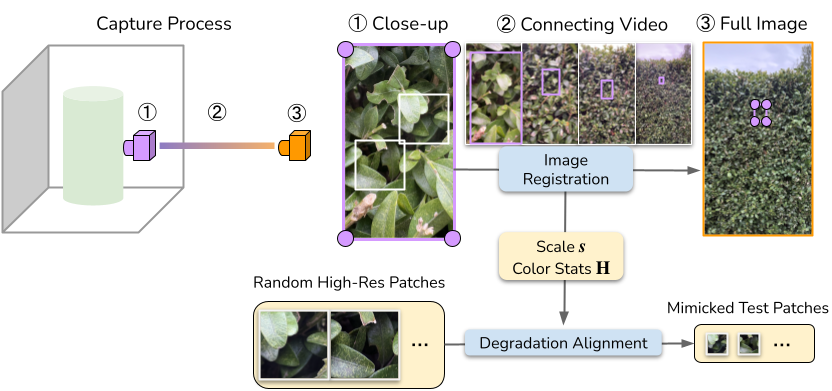
We use an iPhone with macro-lens mode for data collection. Given an object, we capture:
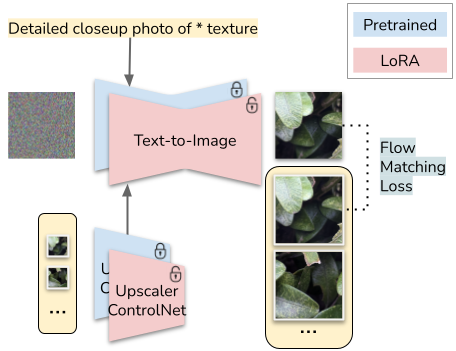
For each object-specific dataset, we fine-tune a separate copy of the model to ensure that the generated details are tailored to that object. The model consists of two components: a text-to-image backbone, which takes a noised image and a text prompt, and a super-resolution ControlNet, which conditions on the low-resolution input. We freeze the pretrained weights and fine-tune lightweight low-rank adapters using the same flow matching objective as in pretraining.

Due to the extremely large output size and limited GPU memory, we split the input into overlapping tiles — as shown here with patches 1, 2, and 3 - and the tiles are processed by the model one by one. To make sure there's no boundary artifacts in the final output, we blend the overlapping regions at the end of each denoising step and after decoding to rgb pixels. We also vary the stride across the denoising steps to avoid repeating the same tile boundaries.
In the end, we have a seamless, gigapixel-resolution output that closely approximates a real captured gigapixel image.
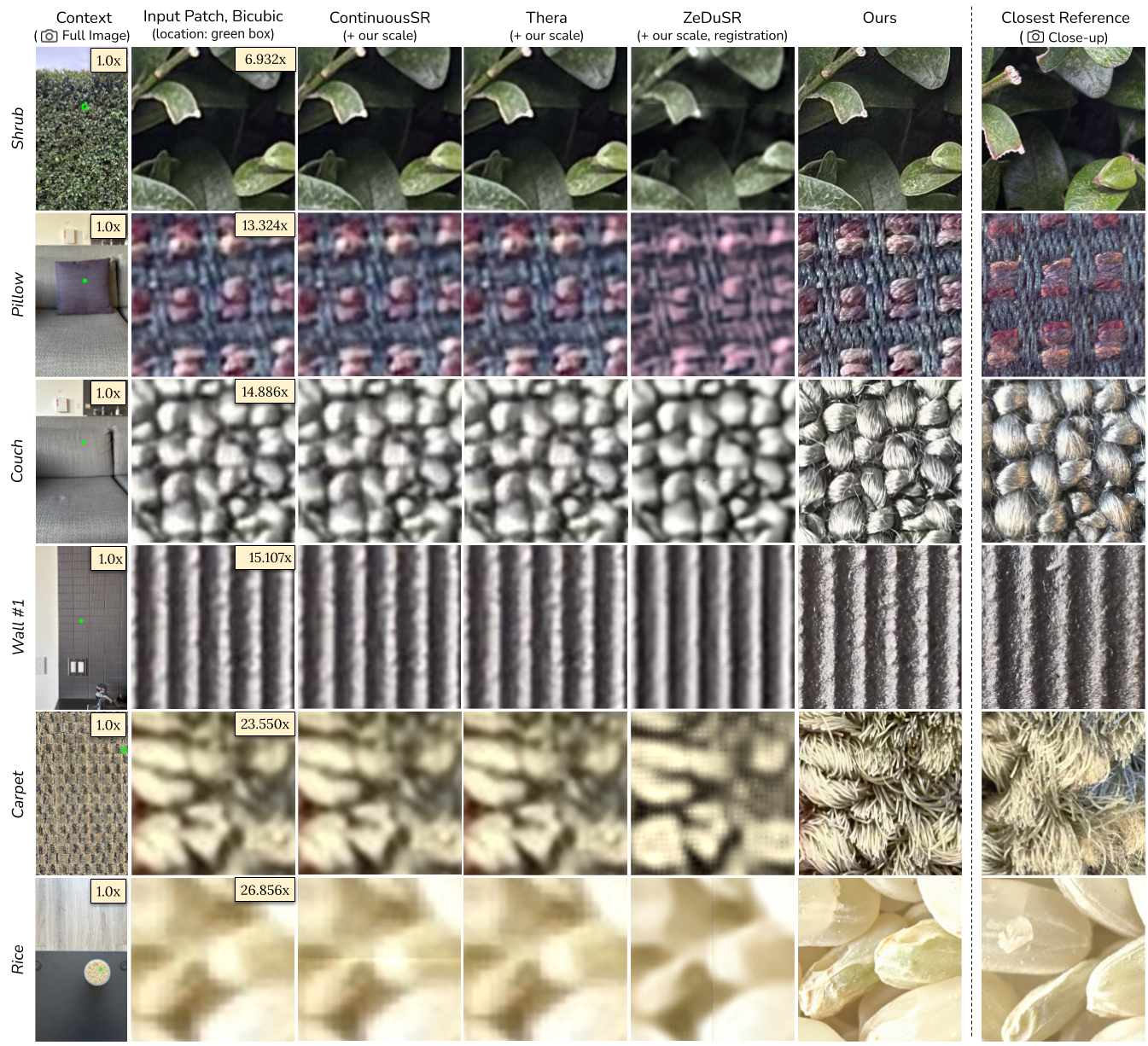
We compare our method with three baselines across several examples: each row corresponds to a different object, ordered from low to high scale. The first two columns show the full-view image with the input patch location (green box) and the low-resolution patch bicubic-upsampled to 1024×1024. The next four columns display results from the three baselines and our method. The final column shows the closest matching reference patch from the close-up image, located via our estimated registration. Note that the input patch and the reference patch are not pixel-aligned, as they come from separate captures taken at different distances.
Qualitatively, our method achieves the highest visual fidelity and consistency with the reference. Even when provided with our estimated scale, ContinuousSR and Thera, two general-purpose, arbitrary-scale super-resolution models, struggle due to domain gaps in scale and field of view. ZeDuSR also performs per-instance fine-tuning, but constructs paired data by aligning close-up and full-shot images. Even with our estimated registration, this alignment often fails due to significant appearance differences (e.g., foreshortening, disocclusion). In contrast, our approach generates training pairs solely from the close-up via degradation alignment, which guarantees pixel-alignment between input and output.